Data Platform Organization~企業のデータ活用3つのステップとデータチームの構築方法~

2020年2月13日に開催したFLEXY主催のCTO meetupは「Data Platform Organization」と題し、データ活用に関するパネルディスカッションを行いました。
内容はデータ活用の定義から具体的な活用事例、そしてデータチームの作り方までを網羅しました。
【ご登壇者】(写真: 左から) 株式会社ユーフォリア CTO 安達輝雄さん JapanTaxi 株式会社 取締役CTO 岩田和宏さん 株式会社グロービス プロダクトマネージャー 宮島弘行さん(ファシリテーター) Supership株式会社 取締役CTO 山崎大輔さん 株式会社マクアケ 執行役員 CTO 生内洋平さん
既にデータチームがあるもののデータ活用が上手くいっていない企業のご担当者、そもそもデータの活用をどうすればよいか考えている企業、更には今後データエンジニアとして活躍していきたい方など、企業のデータに関わる方必見のレポートです。
目次
データ活用を定義するための3つのステップ
 ファシリテーター
株式会社グロービス プロダクトマネージャー 宮島 弘行さん
グリーで開発エンジニアを1年半務め、リクルートマーケティングパートナーズに転職。高校生向けのオンライン学習サービス事業などにおいてWebディレクションやWebマーケティングに注力する。 その後はLINEに参画し、広告や機械学習のプロダクトマネージャーを経験。 データ×PMというポジションを確立する。カカクコムに転職後はマネージャーとして食べログのデータサイエンスチームの立ち上げを推進。 現在はグロービスにてデータサイエンス組織立ち上げとデータ活用を推進中。
ファシリテーター
株式会社グロービス プロダクトマネージャー 宮島 弘行さん
グリーで開発エンジニアを1年半務め、リクルートマーケティングパートナーズに転職。高校生向けのオンライン学習サービス事業などにおいてWebディレクションやWebマーケティングに注力する。 その後はLINEに参画し、広告や機械学習のプロダクトマネージャーを経験。 データ×PMというポジションを確立する。カカクコムに転職後はマネージャーとして食べログのデータサイエンスチームの立ち上げを推進。 現在はグロービスにてデータサイエンス組織立ち上げとデータ活用を推進中。宮島弘行さん(以下、宮島):まずはデータ活用についてディスカッションしていきたいと思いますが、その前にまず「データ活用とは何か?」という点をみなさんと認識合わせできればと思います。
以下の図のようにデータ活用にはいくつか段階があり、まずは基礎集計やデータ可視化、その次にビジネスアナリティクスのような領域、その上に統計・機械学習という領域があると考えています。土台としてデータ基盤と書かせてもらっていますが、これはそもそもデータがきちんと使える形で集約されていないと、どのステップも進められないということです。 データ基盤はインフラに近い部分なので、データ活用という点ではまず上記のステップ1~3にフォーカスして議論していきたいと思っています。
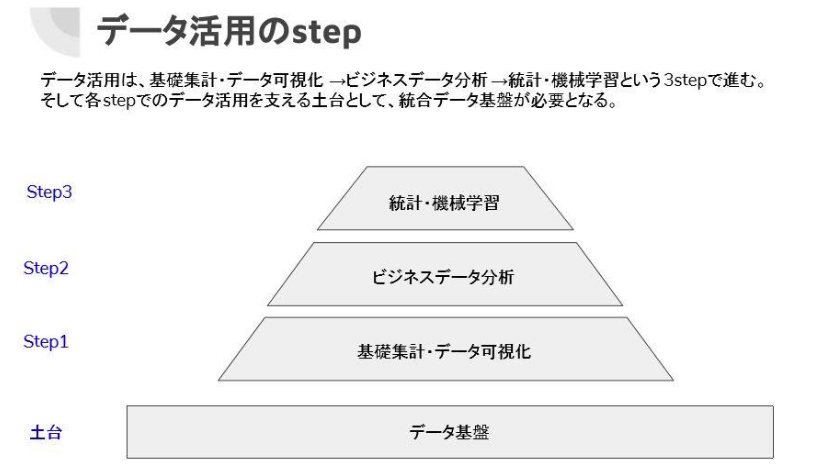
各社のデータ活用の状況と成功事例
宮島:まずは各社のデータ活用の具体例や成功事例などを伺っていきたいのですが、岩田さんからいかがでしょうか。JapanTaxiは配車の最適化などあるかと思いますが。
岩田和宏さん(以下、岩田):成功事例は配車支援システムがありますね。基本的にタクシードライバーの方は一度車庫から出たらあとは好きなところへ行ってお客さんを乗せて営業収益を上げる形になっているので、完全に歩合制です。ですが新人ドライバーさんは道がわからないし、どこへ行っていいのかもわからない。なので配車支援システムを利用して、ドライバーさんがタブレットに示されるルート通りに走ればどんどんお客さんを拾えるようにしました。新人さんであっても平均年収くらいは素早く稼げるようになっているので、成功モデルの一つだと思います。
宮島:まさにステップ3の機械学習のところですね。データ可視化やビジネスデータ分析もすでにやられている感じですか?
岩田:基本的にデータウェアハウス(DHW)を基盤として構築していますね。あとはBI(ビジネス・インテリジェンス)チームがあるので、そこがステップ2のビジネスデータ分析を行なっています。新機能やサービスを開発する際にどんな指標やKPIを測るか決めて、データの変化は全てslackに流れるようにしています。その上でまた別にAIチームが存在する感じです。
 JapanTaxi株式会社 取締役CTO 岩田 和宏さん
大手企業で画像処理系の研究開発、外資系ベンチャーでの医療用の3D画像診断アプリの開発、スタートアップベンチャーにてスマートフォンやweb開発に携わる。 mixi、ストリートアカデミーCTOを経て現在はJapanTaxiでCTOに就任。 また、フリークアウトとJapanTaxiのジョイントベンチャーである株式会社IRISにて取締役CTOを兼務。 マイクロ金融資産活用を推進するPollet株式会社を初め複数の技術顧問を務めベンチャー企業の支援も行なっている。
JapanTaxi株式会社 取締役CTO 岩田 和宏さん
大手企業で画像処理系の研究開発、外資系ベンチャーでの医療用の3D画像診断アプリの開発、スタートアップベンチャーにてスマートフォンやweb開発に携わる。 mixi、ストリートアカデミーCTOを経て現在はJapanTaxiでCTOに就任。 また、フリークアウトとJapanTaxiのジョイントベンチャーである株式会社IRISにて取締役CTOを兼務。 マイクロ金融資産活用を推進するPollet株式会社を初め複数の技術顧問を務めベンチャー企業の支援も行なっている。
宮島:Supership株式会社の山崎さんはいかがですか?
山崎大輔さん(以下、山崎):ビジネスデータ分析の話をすると、弊社のデジタル広告配信システムでは、さまざまなメディアからの月間にして約5000億ものアクセスの中から、そこに紐づくデータに基づいて最適な広告を出しています。みなさんがWebページを見るときに表示されている広告は、1回表示されるごとに裏側では複数の広告主向け広告配信プラットフォームによるオークションが行われていて、入札で勝ったプラットフォームの利用主が実際に広告を表示する権利を得ており、我々はそこを収益としています。この仕組みをRTB(リアルタイムビッティング)と呼びます。 先程約5000億と言いましたが、実際オープンに買える広告在庫は月間1兆ほどあります。これらを1つ1つ人の目で確認してするのは現実的には難しいです。しかし、広告枠が投資に値する在庫なのかは調べる必要があります。そこで行なっているのがビジネス分析ですね。収益が上がっている在庫はどこなのかを学習して、どんなページを閲覧しているどんなユーザー属性なら広告を出して効果が期待できるかといったことを細かく削ぎ落として判断した結果、5000億にまでアクセスを抑えられています。
 Supership株式会社 取締役CTO 山崎 大輔さん
ヤフー株式会社を経て広告配信システムを提供する株式会社スケールアウトを起ち上げ独立。 CEOとしてDSP/SSP開発を行う。 その後、2015年株式会社スケールアウトが吸収合併によりSupership株式会社へ。 取締役CTOに就任し現在に至る。 月間一兆アクセス規模のシステム構築を担うほか、社内インフラの開発・構築も推進する。
Supership株式会社 取締役CTO 山崎 大輔さん
ヤフー株式会社を経て広告配信システムを提供する株式会社スケールアウトを起ち上げ独立。 CEOとしてDSP/SSP開発を行う。 その後、2015年株式会社スケールアウトが吸収合併によりSupership株式会社へ。 取締役CTOに就任し現在に至る。 月間一兆アクセス規模のシステム構築を担うほか、社内インフラの開発・構築も推進する。宮島:ステップ2と3の両方があるという感じですね。株式会社ユーフォリアの安達さんはいかがでしょうか。
安達輝雄さん(以下、安達):当社が提供しているのはスポーツ選手のコンディショニングやトレーニングに必要な情報を一括して記録・管理できるシステムなので、基礎集計とデータ可視化の部分をビジュアライズするサービスと言えます。ステップ1はばっちりこなしていますね。 ビジネスデータ分析に関しては、選手が入力した個人データやチームの状況を掛け合わせた上で改めて選手やスタッフに届けるという意味で当てはまっていると思います。トップアスリートのチームはデータの細かい部分まで見るので、BIツールなどを裏側で走らせて分析し、レポーティングもしています。 ステップ3の統計については、いろんな角度からパフォーマンスを判断するための統計値を導き出しており、すぐに確認できるようになっています。競技や年齢別に統計を分析して、トップアスリートを目指す人たちに還元できるような情報にする仕組みも開発中です。機械学習についてはまだあまり活用できていない状況です。
 株式会社ユーフォリア CTO 安達 輝雄さん
株式会社ユーフォリア CTO 2009年に「クラウドAMAZON EC2/S3のすべて」を執筆。インフラエンジニアからはじまりRuby on Railsのアプリケーション開発もこなすように。DevOpsが流行り始める前からインフラ/アプリの垣根を越えた開発を実践。ONE TAP SPORTSではサービス設計から運用まで幅広く従事。
株式会社ユーフォリア CTO 安達 輝雄さん
株式会社ユーフォリア CTO 2009年に「クラウドAMAZON EC2/S3のすべて」を執筆。インフラエンジニアからはじまりRuby on Railsのアプリケーション開発もこなすように。DevOpsが流行り始める前からインフラ/アプリの垣根を越えた開発を実践。ONE TAP SPORTSではサービス設計から運用まで幅広く従事。
宮島:幅広く取り組まれていますね。株式会社マクアケの生内さんはどうですか?
生内洋平さん(以下、生内):マクアケは2年前まで30人規模の組織で今は従業員60名ほどに成長していますが、基本的に全員データ分析をしてほしいという感覚があります。実際、ステップ2までは誰でもできる状態を目指しています。統計レベルは、部署で1人くらいはできてほしいという感じでしょうか。データを分析する基盤については、プロダクトマネージャー層を中心に整備プロジェクトをハンドリングしています。 また、全社的にデータ活用を意識する中で大事にしているのが「内容は一緒だが違うデータ」という話です。これは、データが同じであっても前提が違えば捉え方が全く違う、ということですね。最も大切なことは、捉え方が違うと未来が異なる。今は同じ内容に見えていても、数ヶ月後には全く違う分析になっているわけで、ここはデータの非常に面白いところです。 例えば年齢というデータにしても、UXとCS視点では解釈が異なります。UXはサービス訪問者の年齢層を把握しますし、CSは対応者のプロファイルとして年齢を把握します。ここを理解することを重視しているわけです。 その上でデータ分析をすると、かなり深みが出てきます。例えば、営業と経理では認識している売上額が違い、営業は「多い」と言っているが経理は「少ない」と言っているということがあれば、「実はキャンセルが増えていた」という話になる。こうした発見ができる組織を作ることを意識しています。
 株式会社マクアケ 執行役員 CTO 生内 洋平さん
大学在学中から通算7年のインディーズミュージシャン・デザイナー・エンジニアの3足のわらじ生活を経て独立創業。 以後、国内外、大手・スタートアップ問わずプロダクトチームへの参加を経て株式会社Socketを創業、CTOとしてWEB接客ツールFlipdeskの立ち上げ〜グロースまでを指揮。 2015年にKDDIグループSyn.HDに参加し、Supership株式会社CTO室での業務を経て、2017年にSupership株式会社を退社。 2017年12月、株式会社マクアケ執行役員CTOに就任。
株式会社マクアケ 執行役員 CTO 生内 洋平さん
大学在学中から通算7年のインディーズミュージシャン・デザイナー・エンジニアの3足のわらじ生活を経て独立創業。 以後、国内外、大手・スタートアップ問わずプロダクトチームへの参加を経て株式会社Socketを創業、CTOとしてWEB接客ツールFlipdeskの立ち上げ〜グロースまでを指揮。 2015年にKDDIグループSyn.HDに参加し、Supership株式会社CTO室での業務を経て、2017年にSupership株式会社を退社。 2017年12月、株式会社マクアケ執行役員CTOに就任。宮島:ありがとうございます。 私もグロービスではデータ活用をしていますが、まだまだスタートした段階なので土台づくりからやりました。今は一段落して、ステップ1のデータ可視化のために事業上必要なKPIのダッシュボードを作ったりしています。 ステップ2の部分で言うと当社には「グロービス学び放題」という、動画でビジネスナレッジを学べるサービスがあります。3分程度の短い動画を中心に公開しているので、通勤時間などのスキマ時間に使用できます。取り上げているテーマは幅広く、経営の3要素と言われるヒト・モノ・カネに加え、グロービスならではのコンテンツとしてテクノロジーとイノベーションをかけ合わせた「テクノベート」や「志」といったコンテンツも用意しています。 サブスクリプション型のサービスなので、継続利用率を向上させるためのビジネスデータ分析をしています。ステップ3の統計については、グロービス学び放題のクライアント毎のLTVを予測しかつLTVに寄与する要因を特定するためにベイズ統計モデリングを用いています。一方の機械学習についてはグロービス学び放題における学習コンテンツのレコメンドが代表的な活用事例になります。
データ活用にまつわる失敗例
宮島:では逆に失敗事例があればお伺いしていきたいと思います。
生内:先程データは内容と前提の掛け合わせを意識していると言いましたが、これは失敗談に基づいています。ここを理解しないままデータ基盤を作っても、何も起きなかったんです。
宮島:なるほど。うちもダッシュボードによって同じ指標を表示しているのに数値が違うといったことがありますよ。それも前提の話ですよね。どんなデータを使っていてどういう定義で集計しているかが違うとズレが起きてしまいます。
生内:ありますね。言葉の定義は大事です。「売上」というのもすごく怪しい言葉ですし。
宮島:そうですね(笑)。安達さんはどうですか?
安達:うちのサービスはアスリートがコンディションなどの情報を入力して、いろいろなデータを掛け合わせて現在の数値として見せるのですが、リリース当初過去のデータを使いすぎたことがあります。「感覚的に何だかこの結果は違う」と選手からフィードバックをもらいました。ただ、一部の人はそのデータで合っていると感じてもいる。人によってバラつきがでてしまったので、アルゴリズムを少しずつ見直しし、改善していくことで落ち着きました。過去のデータを使えばいいものではない、という失敗ですね。
山崎:BIで起きた失敗があります。ビジネスユニットごとに売上を正確に把握するための数字を出せるようにしたのですが、数字が見えすぎて些細なことが気になるようになってしまいました。ある数字が前年比で落ちていたので調査をしたら、前年はたまたまラッキーヒットが合ってセールスが伸びていただけだった。数字が見えすぎたがゆえに余計な仕事を増やしてしまったケースです。
宮島:私も前職で数字を週次でモニタリングしていましたが、同じようなことがありましたね。
岩田:うちの場合指標はデイリー、ウィークリー、マンスリーのうちどれで見るのか分けています。最初はどんどんデイリーで数字を出していたのですが、大した変化もないのに数字が多すぎたんですよね。どのタイミングで数字を見るのが適切なのか、かなり整理しました。
山崎:同じような数字が並んでいるとかえって見なくなってしまいますしね。
宮島:各社さん数字の定義には悩まれていますね。
データの基盤はどのように構築されているのか
宮島:ここまではステップ1~3についてお話ししてきましたが、土台としてご紹介したデータ基盤についても少し伺えればと思います。
岩田:分析用の基盤は全部BigQueryに寄せていて、今はLookerというツールを使って可視化することを基本としていますね。もちろんDWHの中でもデータによっては1次加工、2次加工するなど、違うデータベースセットを作ったりします。一般的な感じです。
山崎:先ほど説明した広告配信プラットフォームはオンプレミスでサーバ運用しています。サーバ台数で言うと1000台くらいですね。分析はHIVEとSparkで行っているのですが、さらにAWSにDatabricksというSparkのマネージドサービスも使っています。 なぜマネージドサービスが全盛の中オンプレで運用しているのかというと、ここはコストの問題ですね。試算してみると3倍ほど違います。広告事業という薄利多売な側面もあるビジネスでは今まではこの差を吸収するのは難しかったんです。ただ、最近はAWSやGoogleもかなりコストが抑えられるようになったので、拮抗しつつあります。そろそろマネージドサービスに変えなければいけない方向にはなっていますね。
安達:うちは基本的に選手が入力した情報から統計値を導き出し、リアルタイム画面に表示してあげないといけないんです。そのために非同期処理を活用し、データベースに蓄積していくアプローチにしています。もっとデータ全体を横断した分析をしたい場合はTableauにデータを入れておいて、後からゆっくり解析するという感じです。
生内:データ基盤の概念はうちも岩田さんのところとほぼ同じです。基本的にはAuroraに入っていて、GAなどのデータも含めて前提ごとにETL処理しています。 インターフェースとしてはもともとRe:dashがあったのですが僕が入社した段階で、Metabaseを追加しています。気にしなくていいところをなるべく気にしないために、触れるデータを意味のある形で抽象化できるプラットフォームを探していて、今は、数年前からずっとですがLookerを検討していますね。エンジニアも非エンジニアも一緒にデータ分析していくという視点では、TableauよりはLookerの方がうちに合っている気がしています。
山崎:Lookerは何がいいんですか?
生内:データを抽象化できるところですね。いい感じに前提を含めたデータセットを作れます。予算さえ許せば使いたいです。
岩田:データベースで言葉の定義もできたりしますね。
宮田:岩田さんのところはデータをリアルタイム処理することはあるんですか?
岩田:車両の位置情報は秒間で数台万分処理します。ここはAWSのKinesisでさばいていますね。
宮島:広告でもリアルタイムデータは使ったりしますか?
山崎:うちは秒間30万リクエストくらいを受けるので使っていますね。

データチームの作り方
データ人材の3つのスキルセットと各ロールの定義
宮島:データチームの作り方についてディスカッションしていきますが、ここでもまずはデータチームにどんな職種の人がいるのかを先に擦り合せたいと思います。
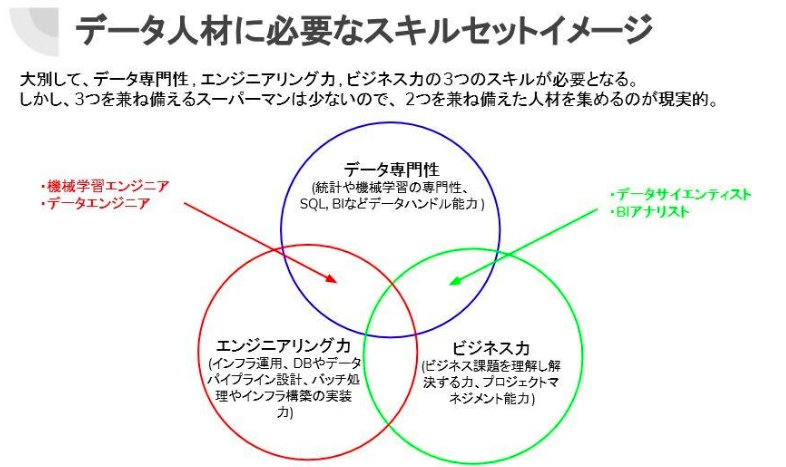
宮島:上記の図はデータサイエンティスト協会が定義している、データサイエンティストに求められるスキル要件の概念図をベースに作成したものです。上記の3要素全てを持っている人が理想ということですが、実際のところそういう人材はあまりいません。 グロービスにおいてはデータ専門性とエンジニアリング力を兼ね備えている人を機械学習エンジニアやデータエンジニアと呼び、エンジニア系職種と定義しています。一方データ専門性とビジネス力を兼ね備えている人はデータサイエンティストやBIアナリストと呼んでおり、これはアナリスト系職種と定義しています。 データ系のチームを作る際にはいろいろな人材が存在しますが、このようにざっくりとエンジニア系なのかアナリスト系なのかに大枠として区切れるかと思います。
ここからさらに職種を細分化すると、以下のようになります。

宮島:上記の区分を踏まえて、各社のチーム組織の状況などをお伺いできればと思います。
各社のデータチームの構成
宮島:まずは岩田さんいかがですか?
岩田:うちはデータ可視化や分析を担うBIチームに5名在籍していますが、基本的にBIアナリストやデータサイエンティスト両方のスキルセットを持っています。 あとはR&Dの部署に次世代モビリティ事業部というものがあり、その中にAIチームがありますね。BIチームとセットになる存在です。取り扱うのは機械学習やディープラーニングで、10数名所属しています。中には国際学会でペーパーを書くようなメンバーもいますよ。この中に2名ほどデータエンジニアがいて、データ整備やプロダクション環境の構築など、機械学習系エンジニアを支えるような業務を担っています。 さらに機械学習エンジニアは位置情報のデータ分析を扱うエンジニアやドライブレコーダーを扱うコンピュータビジョン系のエンジニアなどで専門性が分かれていますね。
宮島:特に機械学習エンジニアの層が厚い感じですね。山崎さんのところはいかがですか?
山崎:オンプレで運用している広告配信プラットフォームのビジネスでは、データエンジニアの層が厚いです。ハードウェアを整備するところからスタートしていますからね。そこを専門で担っているのが3名、データを整えたり広告主が持っているデータソースを解析したりする広い意味でのデータエンジニアも専任で6名ほどいます。さらに例えばAPIを介してSaaSのデータを抜き出す人員なども合わせると全員で12名ほどですね。
宮島:安達さんのところはいかがでしょうか?
安達:うちはまだスタートアップなので25名ほどで構成されています。データエンジニアに関しては私が所属しているSonicGardenのリソースを借りたりもしていますね。データサイエンティストが見たいデータがあり、その分析が難しいようであれば必要に応じてエンジニアに分析を協力してもらうこともあります。 スポーツ業界にもデータサイエンティストはもちろんいますが、少しIT業界の定義とは異なることもあります。どのデータをどう扱いたいかをわかっている職種というイメージで、プログラミング能力が必須であるかというとそうでない場合もあるようです。なので、その際はエンジニアとデータサイエンティストがお互いにフォローし合いながら進める形にしていたりします。 機械学習エンジニアはまだ採用できていません。アプローチとしては機械学習エンジニアにアドバイザーとしてジョインしてもらい、データサイエンティストやデータエンジニアが機械学習を覚えることで自走できるようにしようとしています。
宮島:生内さんはいかがですか?
生内:BIアナリストやデータエンジニアの領域は専門部隊を用意しています。とは言ってもまだ初期段階なので具体的にはBIアナリストを兼ねるようなUI/UXのスペシャリストの部隊から整備を行っていて、ビジネスというよりもエクスペリエンスにフォーカスしています。 もうひとつ、マクアケ自体にはML/DLレベルのデータエンジニアリングの経験者がいなかったので、熱意あるメンバーにコンピューターサイエンスのオンラインラーニングから始まり、Kaggleであったり、大学の講義であったりの基礎知識を学んでもらいました。必要なモデリングは実現できるくらいの感覚を持てています。 この先どんなにML/DLの専門性を向上した施策を行うとしても、内部で開発をハンドリングできるような基礎体制を作る事を優先したということですね。 UXとデータエンジニアだけだとどうしても研究組織のようになってしまうので、ビジネスとのコネクトに関してはプロダクトマネージャーが頑張っています。なのでデータのモデリングに関するベースの知識はプロダクトマネージャーにも求めています。 特にビジネス分析や統計、機械学習のような分野では下手にビジネスアナリストを雇うよりももともと別の専門性を持っているメンバーがデータに興味を持つほうが早いですし、効果も出ますね。自分の専門性へのこだわりとデータへの興味が組み合わさったときのシナジーを期待しています。
宮島:予想通りですが、各社によって違いますね。 最後にグロービスの紹介をすると、当社はもともと非ITの組織だったのですが、3年前から社内でエンジニア組織を作るところからスタートしています。その前提で、今は業務委託も含めて130名ほどの組織に成長していますね。このうちデータ系の人材は4名ほどです。私がプロダクトマネージャーで、あとは統計やビジネスアナリティクスもできるデータサイエンティスト、BIアナリスト、データエンジニアという構成です。まだまだ立ち上げフェーズなので、各ロールにおいて専門性の高いメンバーを1名ずつ入れています。

データチームを作るための「最初の一歩」の踏み出し方
宮島:では、各社がどうやって現在のチーム構成に辿り着いたのか、歴史や道筋のような部分をお伺いできればと思います。
岩田:うちは3年ほど前からデータ系の人材の募集をスタートしました。まずはサービスの解析や分析がマストだったので、BI系の人材を求めていましたね。最初の一人は機動力も含めてゼネラリストのような動きができる人がターゲットでした。 さらに並行してAI系も採用しようとしていたのですが、このときいろいろな人と面談をしていて感じたのが、彼らは会社でどんなデータを扱えるのか、どんなデータソースがあるかを気にするということです。意外と実データを持っている企業は少ないと思うのですが、その点で言うと我々は位置情報や動画像などの実データがあるのでそこを訴求ポイントとしつつ、データソースをどう使えばバリューを生み出せるのかといったポテンシャルについても言語化して魅力として発信しました。その結果、最初のキーマンになるような人材を採用できて、そこから徐々にチームを広げていった感じです。 最近で言うと採用にプラスしてデータエンジニアになりたい社内のメンバーが転向することもあります。統計などは数学的な素養が必要ですが、ある程度条件を満たしていれば社内のプログラマーやエンジニアをデータエンジニアに転向させたほうが採用するよりも早いかなとは思いますよ。
宮島:転向って上手くいくんですか?
岩田:今のところ2、3名転向していますが上手くいっていますよ。最初冗談で「統計検定2級を取ってこい」と言ったら、本当に取ってくるくらいやる気でした(笑)。
宮島:エンジニアとデータ専門性の素養を兼ね備えているのが機械学習エンジニアだと考えると、エンジニアリング力がありなおかつデータに興味がある人は転向しやすいのかもしれませんね。山崎さんはいがですか?
山崎:広告配信システムという関係上集計システムはもともと整備されていて、Hadoop環境もメンバーが頑張っていました。ただ、その上の段階で必要な機械学習エンジニアの一人目は採用に苦戦しましたね。当時私はプロダクトマネージャーを兼ねていて機械学習エンジニアとしては活動できなかったので、とにかく根性で探した感じです。そこから少しずつ人を増やしていきました。 社内のエンジニアには大量配信さえできればいいエンジニアと、営業とタッグを組んで業務プロセスを簡単にすることに情熱を燃やすエンジニアの二通りがいるのですが、今は後者をにあたる人材を集めています。というのも最近はデータドリブンで広告出稿をする流れがあるために、出稿したデータ自体を資産として貯めたいというニーズが出てきたんです。それに伴って、例えばJavaScriptを上手にWebページに貼るだとか、きちんとデータが流れているかウォッチするといった業務も増えてきました。代理店で社内でこれらのデータを見ていたような人が来てくれるケースが多いですよ。
宮島:なるほど。では安達さんのところはどうでしょうか?
安達:うちはなかなか採用できてないというのが現状です。ユーフォリアはスポーツが好きな人が集まっていて、データサイエンスの分野に関しては興味・関心が高い人が多いです。データサイエンティストとして、データをどんどん活用して楽しめるようなエンジニアを求めているのですが、スポーツが好きな人は大体好きなチームもあるので、そのチームが同じ職種を募集していたりするとそちらに行ってしまうこともあるんです。 当社はいろいろなスポーツに携われますし、自分の好きなチームが複数あるならうちでデータ活用するのは楽しいはずという点をアピールしなければと思っています。
宮島:生内さんいかがですか?
生内:マクアケは自社から人材が育ってほしいというタイプですね。国内のプラットフォームとしては中堅規模システムだと思うのですが、数千万レコードくらいまでなら一般のエンジニアでも少し大きめのデータを取り扱ったことがあればデータエンジニアリングができてしまいますよね。それに社内ではデータに興味の無いエンジニアを探すほうが難しいくらいなので、データエンジニアに関してはポテンシャル層がたくさんいるので困っていないんです。スペシャリストに週1で顧問に来てもらえればそれで問題ありません。 この手法をおすすめするもうひとつの理由は、データエンジニア・データサイエンティストは孤独だという側面もあるからです。特に少人数だとアウトプットを誰も評価してくれないということになりがちなので、アウトプットを褒め合えるような仲間がいないと続きません。マーケティング・UX組織の立ち上げと少し似ているところがあります。
採用に勝つにはデータ活用が生み出す付加価値をアピールすべき
宮島:データ系人材は採用難であるという共通認識は皆さんお持ちだと思うのですが、その中で上手く採用するために各社工夫されていることはありますか?
岩田:当社の場合はしっかり露出しています。データのことだけを発信するサイト(誘導先:https://data.japantaxi.co.jp/)もリリースしていて、JapanTaxiがどんな目的を持っているのかをはじめ、タクシーは「センシングカー」と言われていてあらゆるデータを取得できること、さらにどんな分析ができてどんな付加価値が生まれるのかといったことも伝えています。こういったアピールが基本的には大事だと思ますね。
宮島:データの魅力が伝わりますよね。
山崎:うちはデータ量を強みにしています。一般のサイトでは数千億レベルのアクセスにはなかなか触れられませんから、そのあたりをアピールしています。とはいえJapanTaxiさんのような展開はできていないので、これから頑張ろうとしている感じです。
宮島:安達さんは先程のお話のとおり絶賛頑張っている感じだと思うので(笑)、生内さんいかがでしょうか。
生内:あえて言及するとしたら、専門性を取得する一歩手前の、今まさにそこの学習をしようとしているプレ人材をメインに採用するようにしています。チームワークで頑張るよりは一人でも壁を壊せるような人材の方が僕らのフェーズには合っているので、そのフェーズ感を意識しています。
宮島:プレ人材要素に加えて突破力や自走力を兼ね備えている人を採用しているんですね。
生内:そういうものがないと、自分ごととして成果を認識してくれないんですよね。
山崎:プレ人材というのは新卒ですか?
生内:新卒もいますが、基本的には機械学習のプレ人材という意味合いですね。ある程度自分でコードを書いてデータも取り扱っていた経験はあったほうがいいです。
山崎:なるほど。うちは新卒で何名か入っています。彼らは統計などをきちんと学んでいて、その知識を活かせる場を探していくなかでで当社を見つけるようです。当然実務経験はありませんが、プレ人材という意味で新卒を視野に入れるのはアリだと思っています。
生内:先日大学生のプレエンジニアのような人と話したのですが、AWSは分からないけれどKubernetesでWordPress環境は作れると言っていましたよ。技術の進歩を感じましたね(笑)。ぱっと見すごく遠い話に聞こえるかもしれませんが、機械学習業界も同じだと思います。
 【ご登壇者】(写真: 後列、左から)
株式会社ユーフォリア CTO 安達輝雄さん
JapanTaxi 株式会社 取締役CTO 岩田和宏さん
株式会社グロービス プロダクトマネージャー 宮島弘行さん(ファシリテーター)
Supership株式会社 取締役CTO 山崎大輔さん
株式会社マクアケ 執行役員 CTO 生内洋平さん
【前列】
今回のイベントのPMを務めた株式会社サーキュレーション、FLEXYの松川
ご登壇者の皆様、またご来場いただきました皆様、ありがとうございました!
【ご登壇者】(写真: 後列、左から)
株式会社ユーフォリア CTO 安達輝雄さん
JapanTaxi 株式会社 取締役CTO 岩田和宏さん
株式会社グロービス プロダクトマネージャー 宮島弘行さん(ファシリテーター)
Supership株式会社 取締役CTO 山崎大輔さん
株式会社マクアケ 執行役員 CTO 生内洋平さん
【前列】
今回のイベントのPMを務めた株式会社サーキュレーション、FLEXYの松川
ご登壇者の皆様、またご来場いただきました皆様、ありがとうございました!



