AI技術の可能性と期待値調整 〜AIと企業の付き合い方を5名のAI分野のエキスパートが語る

2020年1月28日に行われたCTOmeetupのテーマはAIです。今回は特にAI分野においてクライアントやユーザーが持つ「期待値」に着目し、5名のAI分野のエキスパートにディスカッションしていただきました。
そもそものAIにできることとできないことは何なのか、成果物に対する期待値調整はどのように行えばいいのか、各企業の具体的な事例にも注目のレポートです。
目次
AI技術の可能性と期待値調整 ご登壇者
AIでできること、できないこととは?
自然言語処理において専門分野の概念理解はまだ難しい
 ファシリテーター
株式会社 オルツ CAIO 長田 恭治さん
2002年MsUnitedグループ計7社を設立、グループ代表取締役会長に就任。グループ会社売却後、2008年iL&D株式会社のCTOに就任。フルスタックエンジニアとして、当時未開のNoSQL、Web APIプラットフォーム開発と共に、社外CTOを複数務め、2016年AiR&D株式会社の代表取締役CTOに就任、複数社の社外CTO、社外VPoE、技術顧問を兼務しながら、汎用人工知能、分散ニューラルネットワーク、分散PDS等の先端開発やAIコンサルティングを行い、2019年株式会社オルツのCAIO(Chief AI Officer)&事業本部長、株式会社オルツテクノロジーズのCAIO(Chief AI Officer)&事業本部長に就任、VPoEも兼ねる傍ら、日本CAIO協会の代表理事、SBIインシュアランスラボ株式会社の社外CTO、株式会社クラブネッツの技術顧問を兼務、2020年AIコンサル系の書籍の出版が決定。
ファシリテーター
株式会社 オルツ CAIO 長田 恭治さん
2002年MsUnitedグループ計7社を設立、グループ代表取締役会長に就任。グループ会社売却後、2008年iL&D株式会社のCTOに就任。フルスタックエンジニアとして、当時未開のNoSQL、Web APIプラットフォーム開発と共に、社外CTOを複数務め、2016年AiR&D株式会社の代表取締役CTOに就任、複数社の社外CTO、社外VPoE、技術顧問を兼務しながら、汎用人工知能、分散ニューラルネットワーク、分散PDS等の先端開発やAIコンサルティングを行い、2019年株式会社オルツのCAIO(Chief AI Officer)&事業本部長、株式会社オルツテクノロジーズのCAIO(Chief AI Officer)&事業本部長に就任、VPoEも兼ねる傍ら、日本CAIO協会の代表理事、SBIインシュアランスラボ株式会社の社外CTO、株式会社クラブネッツの技術顧問を兼務、2020年AIコンサル系の書籍の出版が決定。
株式会社オルツ CAIO 長田 恭治さん(以下、長田):まず、「AIによってできることとできないこと」というテーマでディスカッションしていきたいと思います。例えば回帰や分類、クラスタリングのようなロジカルな話もありますが、今回は具体的な現場の事例を踏まえて話していければと思います。まず中山さんいかがでしょうか。
カラクリ株式会社 取締役CTO 中山 智文さん(以下、中山):当社がサービスでやっているのは、チャットボットに教師データを教えるということです。質問に対していい感じの回答を返すということですね。答えがある程度出せる内容であればこれは可能です。 難しいのは、試験問題を解かせるようなことですね。自然言語処理で具体的なものと抽象的なものの間を行き来させるのは一つの課題です。例えば病気に関する問題で、「ワクチンを打つことは一次予防になるか二次予防になるか、正誤を答えよ」というものが難しい。一次予防とは病気を未然に防ぐことで、二次予防は早期発見することなのですが、正解するには具体的に「ワクチンを打つ」という行為が「未然に防ぐこと」であるとわかった上で、さらに「未然防ぐこと」が「一次予防である」という二段階を踏まなければいけません。データが大量にあれば覚えられるのですが、試験問題のようなものは具体的な事例が無数にあるので、全て用意するのは大変なんです。
 カラクリ株式会社 取締役CTO 中山 智文さん
大学在学中にフリーランスエンジニアとして独立。ウェブ開発、スマートフォンアプリケーション開発、ビッグデータ処理、統計データ分析などの仕事に従事。大学卒業後シリコンバレーに留学。情報セキュリティについて学ぶ。2016年4月東京大学大学院に進学。現在は博士後期課程に在籍し、機械学習の応用研究に従事。2016年10月カラクリ株式会社CTOに就任。カスタマーサポート領域の自動化、効率化を進める製品群を開発している。
カラクリ株式会社 取締役CTO 中山 智文さん
大学在学中にフリーランスエンジニアとして独立。ウェブ開発、スマートフォンアプリケーション開発、ビッグデータ処理、統計データ分析などの仕事に従事。大学卒業後シリコンバレーに留学。情報セキュリティについて学ぶ。2016年4月東京大学大学院に進学。現在は博士後期課程に在籍し、機械学習の応用研究に従事。2016年10月カラクリ株式会社CTOに就任。カスタマーサポート領域の自動化、効率化を進める製品群を開発している。長田:チャットだとトークスクリプトベースなのかというところもありますよね。
中山:チャットだとそうですね。概念の理解はもう少し時間がかかります。今は大量のデータをいかに適用するかという技術が発展してきていて、GoogleがBERTなどの技術も出しました。あれを使うと大きなデータセットから抽象概念を抽出するということがある程度できるので、飛躍的に伸びた性能処理の技術はあるのですが、専門知識となるとまだまだ難しいです。データアセットが少ない、あるいはデータそのものが世の中に存在していませんから。
長田:自然言語処理は答えがあるようで無いんですよね。時武さんどうですか?
株式会社LegalForce 取締役CTO 時武 佑太さん(以下、時武):当社は契約書を自動的にレビューしてくれるLegalForceというSaaSのサービスを開発しています。内部では自然言語処理を使っているのですが、AI導入にあたり最初はデータを集めるところから始めました。データ無しでも学習できるケースもあるのですが、契約書のようにトピックが決まっている場合はデータが無いと厳しいです。 データが集まるまでは旧来のナイーブな自然言語処理を使ってアプローチしていました。それでも十分ユーザーさんに使っていただけるクオリティは出せていたので、最初から機械学習をガッツリ使っていたわけではなく、結構地道なアプローチで進めてきた感じです。 なのでできないことという視点で言うと、そもそも最低限の前提条件データが揃っていないと何もできない、というのがLegalForceの開発を通して得たことです。
長田:僕も自然言語処理をやっていたりするのですが、リーガルのような難しい文章の処理は全く想像がつかないです。
時武:契約書はある程度書き方が定まっているので、本当の自然言語や手書きの手紙なんかに比べるとやりやすいと思います。
長田:なるほど、自然文章よりはやりやすいんですね。
AIによる画像解析を導入する前に立ちはだかる環境の壁
長田:では次に金田さんお願いします。
株式会社フューチャースタンダード CAO 金田 卓士さん(以下、金田):僕がいつも考えているのは、AI以前と以後で何が一番違うのかなということです。これまでは何かやろうとしたら、全てロジックを積み上げてプログラムを書いていました。一方でAIはデータとそれに対する評価関数を定義できれば、内部は帰納的にコードに落とせるのが一番の特徴ではと思っています。となると、やはり適切な評価関数を設定できるかどうかが最も意識するところですね。 あとは僕がやっている映像という意味で言うと、技術的にアルゴリズムで開発はできるけれども、実導入という面では価格やスペックがハマらないことがあります。本当は4Kで撮れれば解析ができるけれども、現場のスペックではできないということもある。そこは時代が進めば可能になる部分かなと思います。
 株式会社フューチャースタンダード CAO 金田 卓士さん
大学院では計量経済学を専攻し、卒業後は一貫してデータ関連の業務に従事。一休.com、SBテクノロジーを経て、VASILYではデータ分析チームの立ち上げや分析基盤構築などを通じてデータドリブンな組織への変革を主導。2016年よりフューチャースタンダードへ参画し、映像解析に関する事業開発やR&Dの責任者を務めている。
株式会社フューチャースタンダード CAO 金田 卓士さん
大学院では計量経済学を専攻し、卒業後は一貫してデータ関連の業務に従事。一休.com、SBテクノロジーを経て、VASILYではデータ分析チームの立ち上げや分析基盤構築などを通じてデータドリブンな組織への変革を主導。2016年よりフューチャースタンダードへ参画し、映像解析に関する事業開発やR&Dの責任者を務めている。
長田:画像は私もよく現場でぶち当たっている問題ですね。画像解析するときはもちろんデータ量も必要なのですが、そもそも論としてAIで解析するための画像を撮影する環境を整えましょうということになる案件が非常に多いです。どちらかと言えば環境整備8割、AI導入が2割くらいですね。すると結局投資対効果のような話になるので、そこはパネルディスカッション2部でお話する予定の期待値調整が絡みます。AIに関してよく分かっていないまま着手すると、AIへの信頼度が下がってしまうということです。 当社の話をさせていただくと、先日AI GIJIROKU(AI議事録)というツールをリリースしました。そのとき非常に多かったのは、「100%の精度が出るんですよね」という声です。でもパネラーの方も会場の皆さんも同じ考えだと思いますがAIに100%はありません。それは営業現場でもはっきり伝えます。70、80%を精度の落とし所としたときに残りの部分をどう調整すれば実用に耐えるのか、という話が通じればプロジェクトがスムーズに進むのかなという気がします。AIが目的化してしまうと難しいですね。
時武:ヒューリスティックにやっていくとデータを入れても最初はどうしても精度が出ないんですよね。とりあえずPoCを作って「こんな機能ができます」と弁護士さんに話すと、その段階でも「すごいじゃないか」という話になるのですが、そのままリリースするとユーザーさんから「80%の精度では使えない」と言われる。内部の弁護士とユーザーの認識に差異があるなと感じますね。
 株式会社 LegalForce 取締役CTO 時武 佑太さん
東京大学大学院 情報理工学系研究科創造情報学(修士)修了。 ソフトウェア工学に関する研究を行う傍らWebサービス開発に携わる。 2016年4月 株式会社ディー・エヌ・エーに新卒入社し、アプリエンジニアとしてヘルスケア事業に従事。 2017年9月 株式会社LegalForceに参画し現職。 2019年11月 CTO of the year 2019受賞。
株式会社 LegalForce 取締役CTO 時武 佑太さん
東京大学大学院 情報理工学系研究科創造情報学(修士)修了。 ソフトウェア工学に関する研究を行う傍らWebサービス開発に携わる。 2016年4月 株式会社ディー・エヌ・エーに新卒入社し、アプリエンジニアとしてヘルスケア事業に従事。 2017年9月 株式会社LegalForceに参画し現職。 2019年11月 CTO of the year 2019受賞。AIは果たして「意味」を理解しているのか?
長田:一旦話を戻します。AIにできないことに関して例えば複雑な知覚操作はできないということがあると思いますが、これは徐々に進化する可能性がありますね。あとは高度なコミュニケーションなどでしょうか。
中山:文脈を考えた高度なコミュニケーションはできていない部分が結構ありますね。
長田:「AIは意味を理解していない」と言われることは多いですよね。
中山:理解していると言いたいですけどね(笑)。「意味」とは何かというところがあります。
長田:そこは定義が難しいですよね。「記号は理解している」という言い方も多いですし。一方で意図解析エンジンのようなものもあったりますし。
中山:目的に応じて意味は変わるので、そうなると軸が変わるわけですよね。自然言語処理でいう「意味」は意味ベクトルや意味空間を数値で表して多次元空間にマップすることを指したりしますが、それも一種の解釈ですから。文脈によっても違うので、やっぱり難しい。意味というものを人類がまだ理解していないという部分があります。
長田:「意味」とはなんぞや?というところですね。
中山:「意味」の意味とは?ですね。
長田:そのあたりはAI研の方々の大好物の話だったりしますね(笑)。 逆にできることを金田さんにお伺いしたいのですが、例えば映像解析の分野ではどんなことが実現可能になっていますか??
金田:Object DetectionとかPose Estimationは研究段階ではなく既に実用段階ですね。そういったアルゴリズムを使いやすくして、実際のビジネス課題の解決に応用するということをやっています。
長田:ありがとうございます。AIは昔から取り組まれていますがまだまだこれからの若い業界です。ディープラーニングが流行っているという文脈で言えば、やはり予測や検知に関する回帰モデルであったり、クラスタリングは間違いなく「できる」と言い切って良いでしょう。100%ではありませんけどね。なので社会実装という意味では精度が出ない部分をどうするのかを考えながらプロジェクトやシステムを組んでいくことが一つの方法になるのだと思います。 あとはやはり学習を継続していくことですね。少しずつできる領域を広げていくことです。BERTもそうですがXLNetのような新技術も登場しています。論文ベースでいろいろと調べつつ、どれがプロジェクトに最適なのか、みなさん試行錯誤されていると思います。
期待値調整をするための各社の工夫
長田:ではパネルディスカッション2部に移ります。期待値調整の部分は自社サービスなのかクライアントベースなのかというところで違うと思いますが、みなさんはどのような工夫をされているでしょうか。
中山:サービス導入の場合は営業マンが全体設計の中にサービスを盛り込んで期待値調整をするのですが、研究開発にもAIの期待値調整が必要な部分があると思います。そういうときは簡単に回せるものはすぐに回すようにしていますね。最近はそれも手軽になってきていて、うちの場合はGoogleのCloud AutoMLなんかをよく使います。画面のボタンを押していけば5分くらいでデータをアップして、何らかのモデルを作れるんですよ。すぐに結果が出るか出ないかがわかります。そこまでを無償でやることもあるくらいですね。AutoMLの使い方を先方に教えることすらあります。 これは期待値調整に失敗してしまう方が会社にとって損害だからです。簡単に調べられる部分は最初に調べてしまいます。
長田:最初のアセスメントの段階でそこまでやってしまうということですね。
中山:そこは世の中の環境も整ってきていますからね。そんなに難しくありません。逆に整っていないのはデータの方です。パネルディスカッション1部でデータとなる撮影をするところから始めるという話がありましたが、リスクが大きくないですか?
長田:当社の文脈で言うと先方の課題解決や社会実装が目的なので、コンサルティングも含めてプロジェクトが成功するように持っていくことが道筋になっています。そういう意味でどうしてもやらざるを得ないところですね。
中山:でも、データを作成しても結果が出るかどうかわからないですよね。
長田:そこは今あるデータを使ってアセスメントします。検証をした結果、「今御社にある画像では厳しいので、環境改善しましょう」という方向になる場合もあります。 時武さんは期待値の部分についていかがでしょうか?
時武:業界柄もあるかもしれませんが、内部と外部、2つの期待値調整があると思っています。内部は社内の弁護士やビジネスサイドの人たちで、外部がユーザーですね。うちの場合内部の期待値はそんなに高くないんです。検索エンジンを使って契約書の検索ができるようにしただけで「すごいじゃん!」と言われるくらいで(笑)。
長田:羨ましいですね(笑)。
時武:なので内部の期待値調整は楽でしたし、簡単に期待値を越えられたくらいの感じでしたね。 一方で外部の期待値調整には苦労しました。弊社の弁護士によると、数年前から法務業界でもAIについて耳にすることが多くなったと聞いています。リーガルテックという分野が話題になっていることも法務分野の方々の間では広く知るところで、「AIが台頭してきた時に自分たちの仕事がどうなっていくのか」という漠然とした不安を持っている方が多かったです。なのでとにかく「法務のための支援ツールである」というスタンスで説明を続けました。完全に業務を自動化するようなサービスではなく、あくまで法務プロフェッショナルの方々が日々の業務に取り入れることで効率化が図れるサービスである、ということですね。 その結果リーガルテックやAIという言葉に過剰反応していた人たちにも「法務の仕事に取って代わるようなものではない」という認識が広がってきて、今は支援ツールと共存していく雰囲気が醸成されていると思います。
長田:グロービスさんはどうですか?
株式会社グロービス プロダクトマネージャー 宮島 弘行さん(以下、宮島):過剰な期待を持たれてしまったケースはありましたね。あるサービスにメディア記事のレコメンド機能を実装してほしいという話があったのですが、そもそもデータが無いので無理だという話をして、リリース段階では一旦実装しないことになりました。やれないことをやれると言ってしまうと双方が不幸になるので、きちんと閉じていく必要はありますね。
中山:効果予測を立てるということですよね。
 株式会社グロービス プロダクトマネージャー 宮島 弘行さん
グリーで開発エンジニアを1年半務め、リクルートマーケティングパートナーズに転職。高校生向けのオンライン学習サービス事業などにおいてWebディレクションやWebマーケティングに注力する。その後はLINEに参画し、広告や機械学習のプロダクトマネージャーを経験。データ×PMというポジションを確立する。カカクコムに転職後はマネージャーとして食べログのデータサイエンスチームの立ち上げを推進。現在はグロービスにてデータサイエンス組織立ち上げとデータ活用を推進中。
株式会社グロービス プロダクトマネージャー 宮島 弘行さん
グリーで開発エンジニアを1年半務め、リクルートマーケティングパートナーズに転職。高校生向けのオンライン学習サービス事業などにおいてWebディレクションやWebマーケティングに注力する。その後はLINEに参画し、広告や機械学習のプロダクトマネージャーを経験。データ×PMというポジションを確立する。カカクコムに転職後はマネージャーとして食べログのデータサイエンスチームの立ち上げを推進。現在はグロービスにてデータサイエンス組織立ち上げとデータ活用を推進中。
期待値調整の失敗を経たAI業界の変化
長田:そもそもなぜ期待値調整という話が出てくるのかという部分もあるかもしれないですね。数年前までAIに対する期待値が社会的に高かったことは皆さんご存知だと思いますが、最近は幻滅期に入っているといわれています。 その理由の一つとして、多くのAI導入の失敗事例があげられると思うのですが、例えば僕が関わったあるAI企業の例ですが、IT業界出身のセールスマンを15人採用したんです。しかし、契約が全く取れずに結果的に全員辞めました。なぜかというと、IT業界は「ソリューションの組み合わせによって課題解決ができる業界」だとするならば、AI業界は不確実性の高いプロジェクトが非常に多く、全体の20~30%はチャレンジングな取り組みばかりで、セールスマンもなかなかお客様に対して強く勧められないという現象が起きる。IT業界の10年選手たちが、IT業界脳で営業してしまった結果、「90%以上の確実性がないと営業はできない」、「リスクを負うのは嫌だ」、ということになってしまった事例がありました。
中山:AI系の会社で上手くセールスしているところはどうやっているんでしょうね。
金田:当社の場合は映像解析のプラットフォームを開発していて、それを活用して、特定の業界の課題を解決するパッケージをバーティカルに立ち上げています。出せる精度もどれくらいの費用なら払ってくれるのかということも見えている。逆に言えば、そこまで落とし込まないと普通の営業マンが売れるようなものにはならないと感じていますね。不確実性の高い案件は、自分や社長がお客様の課題の上流から入って取り組みます。
長田:AI系のプロダクトは割とそうですよね。LegalForceさんはいかがですか?
時武:精度が低いうちはそもそも売りにいきませんでした。客先に行っても「もう少し精度が上がれば買うかな」という反応がほとんどでしたしね。まずは精度を高めるための開発を最優先して、ある程度使えそうだという感触を得てからセールスの人を入れ始めました。
長田:素晴らしい。見習います(笑)。
AI活用のチームを立ち上げるために必要なメンバー構成とは
長田:質問をピックアップしてディスカッションを進めたいと思います。「AI技術を活用するチームを立ち上げる場合、最低限必要なメンバー構成を教えてください。また、立ち上げ期で効果が見えない中でのKPI設定やマネジメントはどうされていますか」という質問があがっていますが、いかがでしょうか。
宮島:僕は前職でも現職でも機械学習チームの立ち上げを経験しているのですが、3つのロールが必要だと思っています。コアになるのがプロダクトマネージャーですね。あとは機械学習エンジニア、そして実際にモデルをサービスに組み込んでいくデータエンジニアです。 機械学習によるレコメンドを最終的にきちんとサービスとして作り込むためにはいくつかステップがあるのですが、最初は企画立案ですね。次にオフラインの性能検証、オンラインの検証、最後にシステム導入です。それぞれのステップで各々がやることはいろいろあるのですが、特に企画立案の段階で「そもそもAIを使ったサービスに事業的価値があるのか」と判断する部分は大事です。あとはどんなデータが必要になるのかという視点と、性能要件ですね。仮にレコメンドリストを1日1回生成したい思ったときに、データ量が多いので生成には24時間かかるということになると要件が破綻してしまいます。システムとして満たすべき要件と実際の性能を担保しなければいけません。その上で実際どんなリターンが期待できるのか幅を持たせて試算して関係者とネゴシエーションしていくのですが、そこでのプロダクトマネージャーの役割は特に重要になります。
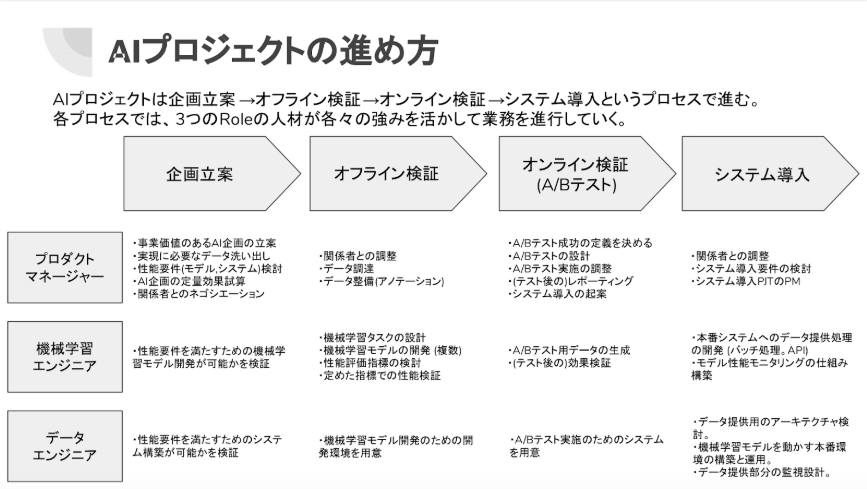
宮島:こういった流れを繰り返す中で、今言った3つのロールが必要になるなという感じですね。 また、立ち上げ期におけるKPI設定に関しては、売上に直結する数字を狙うことをおすすめします。売上をマークすればCTRが上がったことで売上が増えた、といった成果を出せます。わかりやすくてビジネス的に意味のあるKPIを狙いにいって、小さくてもいいから成果を出すのが一番重要だと思いますね。
中山:AI 系のプロジェクトを始める時にデータサイエンティストは必要ですか?
金田:プロジェクトの最初のほうはデータエンジニアやビジネスアナリストのような人を入れて、その次の段階で統計や機械学習ができる人を入れていくのが一番いいのかなと思います。
中山:エンジニア能力が一番必要ですよね。時武さんもLegalForceを立ち上げたときに弁護士さんたちしかいなくて、時武さん自身はAI系のバックグラウンドは無かったですよね。
時武:そうですね、もともとソフトウェア工学専門ですし、今でもまだデータを扱うための専属のデータサイエンティストは採用していません。一番大事なのはデータ基盤の立ち上げや整備で、ここには結構工数をかけました。うちの場合それよりも必要だったのはドメインエキスパートでした。法務の専門知識がある人がいないとどのデータが正しくて正しくないのか判断できなかったので、エキスパート向けのAIソリューションを検討しているのならドメインエキスパートは絶対に必要だと思います。

会場からの質疑応答
AI業界における不確実性高い状態は今後変化していくのか?
長田:では会場の方からも質問をお受けしたいと思います。
【質問者】 IT業界は確実性が高く、AI業界は不確実性が残っているという話でしたが、IT業界も20年前は不確実性が高かったと思います。現在はある程度顧客が自分たちで期待値をコントロールしている状態かと思いますが、今後AIもそういった不確実性や期待値の部分は変わっていくという見込みなのでしょうか。
長田:AIの不確実性が高くなる要素としては、ソリューションが確立されていないという面があると思います。例えばクラウドソリューションならAWSやそのほかのオープンソースソフトウェアが広まっていて、デファクトスタンダードになっています。 一方AI企業はどちらかといえば横の連携でそれぞれが研究開発を進めている段階だったりするんですね。もちろん超大手であるGoogleも巨額の投資をしてオープンソースを発表していますが、それでもまだデファクトスタンダードなソリューションは数えるほどしかありません。もちろん期待値の問題もあるとは思うのですが、やはりまだまだ課題解決の方法を自社の独自技術で提供していることが多い気がします。
時武:ソフトウェア開発の分野は1990~2000年代の多くの失敗の上に今のベストプラクティスが成り立っています。AIも今後同じようにベストプラクティスが確立されていくのだと思いますし、実際5年前に比べればマネージドサービスも拡充してきています。手軽に扱えるフレームワークを使っていくことで、成功へと導けるようにはなっていくんじゃないでしょうか。 一方でAIが複雑なのは、必ずしも思うような結果が出てくるわけではない、といった部分です。そこはツールがいくら発展したとしても、不確実性として残ってくるのかなとは思いますね。
金田:お客様自身も2、3年前に比べるとだいぶAIの知識をアップデートしているなというのは実感しています。以前はそもそもAIで何ができるかわからない、とりあえずAIをやりたいという感じでした。最近はまず一定の課題があり、このアルゴリズムを使えばいけそうだからできる会社を探しているという人も増えてきましたよ。
AI活用のアイディアはあるがリソースが不足している場合の対処法
【質問者】 当社は教育系のベンチャー企業なのですが、子供の感情を分析して何かできたらいいなと考えています。ただ、リソースが全く無いため機能実装がなかなかできません。こういった状況でどう進めたらいいのか、ヒントはあるでしょうか。
宮島:リソースが足りないというのは、実際にモデルを作る人がいないということでしょうか?
質問者:そうです。予算もありません。
宮島:ベストな回答かはわかりませんが、インターン生や大学生なら少し費用が下がるので、入れてみるのはアリかもしれません。
長田:内製するかどうかにもよりますね。
金田:表情から感情を読み取るということであればMicrosoftのFace APIとかで多分できちゃいますね。
長田:チームビルディングの一歩目としてどう準備すればいいのか、という視点で言うとどうですかね。
中山:データサイエンティストはいらないです(笑)。普通のエンジニアしかいなくても、今ある要素の組み合わせでできることはあるような気がします。データセットとして何があるのかということももちろんですし、こんなルールベースならある程度やりたいことができるんじゃないかという直感も働くはずですし。まずはそういう試行錯誤をしてみて、その中で足りない部分が出てきたらこういった勉強会で聞いてみるというやり方ができるのではないでしょうか。
長田:リソースという問題であれば、ちょうどこの会場のサーキュレーションさんに週2、3回入ってくれるAIエンジニアさんがたくさんいますね(笑)。今日ご登壇されているようなハイレベルのメンバーをフルコミットで雇うとなるとやはり相当高額になってしまうと思いますが、週に2,3回のアドバイザリーなどで入ってもらう分には、特に立ち上げ期の場合は有用な一手だと思います。
 写真左から
・カラクリ株式会社 取締役CTO 中山 智文さん
・株式会社LegalForce 取締役CTO 時武 佑太さん
・株式会社オルツ CAIO 長田 恭治さん
・株式会社グロービス プロダクトマネージャー 宮島 弘行さん
・株式会社フューチャースタンダード CAO 金田 卓士さん
写真前方真ん中:
本イベントPMを務めた flexy 小林
ご登壇者、ご来場者の皆様、ありがとうございました!
写真左から
・カラクリ株式会社 取締役CTO 中山 智文さん
・株式会社LegalForce 取締役CTO 時武 佑太さん
・株式会社オルツ CAIO 長田 恭治さん
・株式会社グロービス プロダクトマネージャー 宮島 弘行さん
・株式会社フューチャースタンダード CAO 金田 卓士さん
写真前方真ん中:
本イベントPMを務めた flexy 小林
ご登壇者、ご来場者の皆様、ありがとうございました!



