最強データベース(RDB)設計とは?アンチパターンの見極め方法も

※2020年6月に公開された記事です。
日本PostgreSQLユーザ会の理事を務める合同会社Have Fun Techを起業した曽根壮大(@soudai1025)と申します。元株式会社オミカレ副社長兼CTOです。直近では、『失敗から学ぶ RDBの正しい歩き方』を執筆しました。
今回はデータベースをテーマとして、魅力やMySQLとPostgreSQLの違い、アンチパターンの見極めなどの基礎知識に加え、勉強法などもご紹介します。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込むデータベースを学ぶ魅力をエンジニア目線で考察
1.知識の費用対効果が高い
エンジニアがデータベースを学ぶ利点という観点から言うと、データベースの特徴は寿命が長いことと私は考えています。 Webアプリケーションの界隈では1年単位でバージョンアップしたり流行っている言語が変わってしまうことがザラにありますが、データベースは10年、20年という単位で一度学んだことをずっと実務に生かすことができ、知識の費用対効果が高いです。
例えばブログサイトのデータベースを利用してECサイトを作り、その後ECサイト1本に絞って運営することになった場合、ブログのアプリケーションはなくなってもデータベースは残っている状態ですよね。サイトをリプレイスしたりバージョンアップするようなことはあっても、データベースを捨てるという状況には基本的になりません。
2.データベース設計の重要性
一方、データベースはアプリケーションの土台となる部分なので初期設計や改修に失敗すると長く引きずりやすいという側面もあります。特にスタートアップ企業はデータベースの整備を後回しにしがちなのですが、後から改善するのは基本的に大変です。
長らく付き合っていくものだからこそ最初にしっかり構築すべきですし、スタートアップを目指すような若いエンジニアには早めに学ぶべきでしょう。PostgreSQLでは公式ドキュメントやPostgreSQL Internalsなど無料で公開されているWebドキュメントがあります。
寿命が長い分、データベースの分野はこれまで先輩たちが培ってきた数十年分の知見が書籍やWebに蓄積されています。体系的に学んでいけばプロフェッショナルになれるので、その点も魅力と言えるでしょう。
3. 長期間働けて、高単価で稼ぎやすい
データベースエンジニアは息の長い職種です。仮に結婚や出産で一度職場を1年離れたとしてもその間にデータベースが劇的に変わってしまうようなことはまずありません。職場復帰しやすいので、海外の女性エンジニアでもDBA(Database Administrator)として活躍されている方が多くいます。
また、実際に現場で問題が発生するのは、大体5年とか10年といった単位で育てられたデータベースなのです。ここで押さえておきたいのが、基本的に長期間にわたってデータベースを運用している企業は売上があり、儲かっているということです。なので仕事の単価そのものが高いことが多いですし、そこで課題解決をすることが効果的な営業にもなります。
こういった働きやすさもデータベースのメリットなのです。
4. 初心者の方への参考書籍、まずはアプリケーションを作ることがおすすめ
初心者の方は、データベースを学ぶ上でのおすすめ書籍をご紹介します。
- 『達人に学ぶDB設計 徹底指南書』(翔泳社)ミック
- 『達人に学ぶSQL徹底指南書 第2版 初級者で終わりたくないあなたへ』(翔泳社)ミック
- 『SQLアンチパターン』(オライリージャパン)Bill Karwin
データベースの基礎知識を学べる良書は多いのですが、もしも読者の方の中にこれから初めてデータベースやプログラミングについて学ぼうとしている人がいれば、まずは「作ってみよう」系の書籍に手を出してみるのがいいでしょう。言語はPHPでもRubyでも何でも良いのですが、まずはアプリケーションを作ってみるのが第一歩になります。
日本PostgreSQLユーザ会の理事として様々な方にお会いする中で、一度文系の学生さんからのコメントをきっかけに「文系でもプログラマーになれるのか」というテーマをブログ記事に執筆しましたが、そこでも学習方法として、まずはアプリケーションを作ることをおすすめしています。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込むDBの種類
RDBとは?MySQLとPostgreSQLについて
「RDB」は「Relational Database(リレーショナルデータベース)」の略で、日本語に訳すと「関係データベース」となります。RDBはデータを複数の表として管理し、表と表の間の関係を定義することで、複雑なデータの関連性を扱えるようにしています。
MySQLとPostgreSQLの違い
データベースのソフトウェアはMySQLかPostgreSQLの二強状態です。両者の違いの一例を先日、私が台湾のCOSCUPで使用したスライドをもとにご説明したいと思います。
MySQLとPostgreSQLの大きな違いは以下の3点です。
- architecture (設計)
- license (ライセンス)
- Development style (開発体制)
その中でもアーキテクチャは特徴的な違いがあります。MySQLがマルチスレッドを使い、PostgreSQLはマルチプロセスを使います。マルチスレッドの方が早いと考えるかもしれませんが、実はそうでもありません。
フォークするコストよりもスロークエリのパフォーマンス問題の方が影響は大きく、実際にロングトランザクションのロックに比べればコネクションのコストは微々たるものです。またコネクションプーリングを使うことでコネクションのコストは減らすことができます。
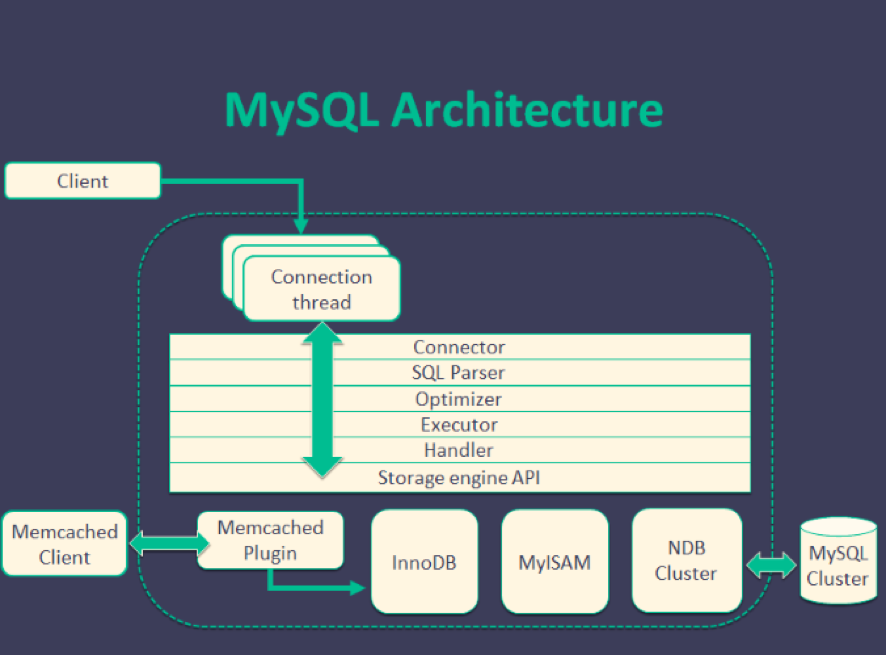 画像:MySQL architecture(台湾のCOSCUPで使用したスライドから引用)
画像:MySQL architecture(台湾のCOSCUPで使用したスライドから引用)
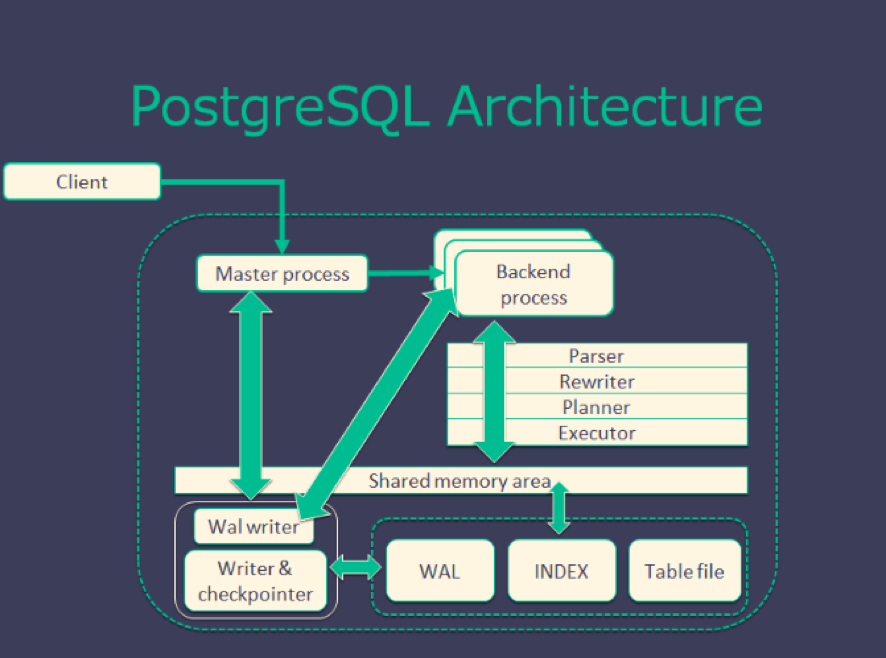 画像:PostgreSQL architecture(台湾のCOSCUPで使用したスライドから引用)
画像:PostgreSQL architecture(台湾のCOSCUPで使用したスライドから引用)
MySQLとPostgreSQLは、データの保存に対する考え方も違います。
MySQLはストレージエンジンを介すことで自由にデータを保存することができます。例えばMySQLでINSERT文を実行し、その保存先はmemcachedにすることができます。制限の無いこの自由度はMySQLの利用用途を大きく広げる特徴です。
PostgreSQLはそれに対して、RDBMSとして厳格にデータを保存しています。PostgreSQL12からプラグイン機能が入ったものの、まだまだ実験的な機能であり、PostgreSQLの本体としては厳格にデータを保存しています。もちろんMySQLもRDBMSとして利用すれば正しく厳格にデータを保存することは出来ますが、PostgreSQLのカラーはレプリケーションにも現れています。
MySQLはスレーブ側に対しても更新や変更ができるのに対し、PostgreSQLはセカンダリに対して更新することができません。
このようにMySQLとPostgreSQLはお互いに影響を与えながらも、個性的なカラーを出しながら発展しています。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込む「良くないデータベース」とは?
RDBアンチパターンを見極める方法
本記事の冒頭で、データベースの初期設定や改修の重要性について触れましたが、データベースは基盤となる部分ですから、摩訶不思議な設計、私はマジカルな設計と呼んでいますが、技術的負債になるような設計をすると仕様変更ができません。基盤が三角形の屋根のような状態になってしまっていて、その上に仕様を乗せることができないのです。
そんなデータベースにリファクタリングを施すにはRDBアンチパターンを見極める必要があります。
私がよく引用するのは『データベースリファクタリング』(Addison-Wesley Professional、2006、日本語版は絶版)にあるリファクタリングが必要となる項目です。「データベースの不吉な匂い」と言われます。
リファクタリングが必要となる項目
複数の目的に使われるカラム
- レコードの属性に合わせて値の意味が変わるカラム
- 会員だと入会日、スタッフだと入社日とするなど
複数の目的に使われるテーブル
- カラムの場合と同様に1つのテーブルが複数の意味を持つ
- Usersテーブルに会員、管理者、事業者などが混在しているなど
冗長なデータ
- 非正規化など
- 生年月日と年齢カラムがあった場合、1年経ったときに年齢カラムが事実からずれてデータの整合性が取れなくなる。
カラムの多すぎるテーブル
- memo1、memo2、memo3…memo99 など
- 複数のエンティティの責務を束ねている可能性がある
行の多すぎるテーブル
- データを削除しないテーブル
- 削除が怖いために論理削除で対応するなど
- 本当にデータの行数が大きくなるテーブルならパーティションなどを検討する
「スマート」カラム
- データの中にビジネスロジックなど、データ以上の意味を持っているもの
- 9から始まるidは管理者、1から始まるidはユーザーなど
変更の恐怖
- データベースの変更やデータの更新によって、アプリケーションが壊れるのでは? という恐怖があって手を付けれない状態
「データベースの不吉な匂い」の実例も見てみましょう。例えば以下の値は破綻しています。
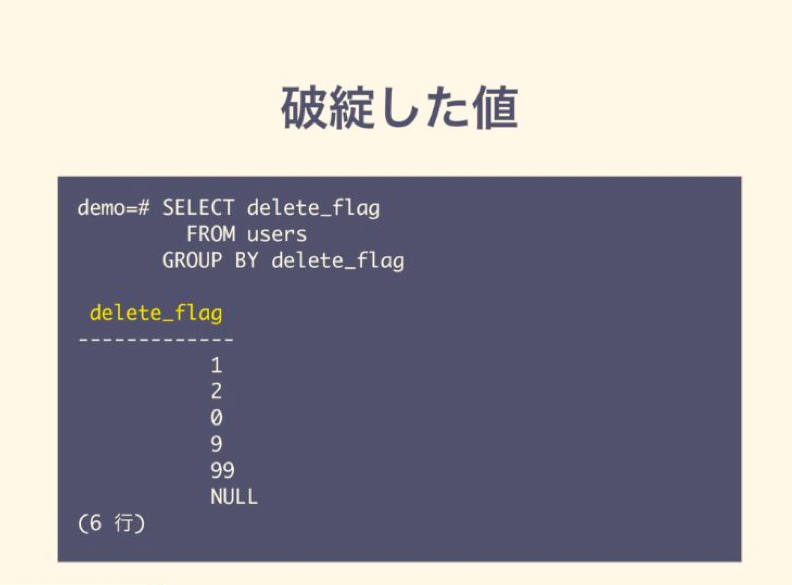
こういった「データベースの不吉な匂い」を見つけたら、まずリファクタリングをする意味があるのか、作業工数に対してどれくらいの効果があるのか、そしてそれを今すぐやるべきなのかという点を検討して優先順位付けを行う必要があります。
実際にこの破綻した値は「失敗から学ぶ RDBの正しい歩き方」の中でも「データベースの迷宮」と名付けたアンチパターンとして扱っています。
では、最強のDB設計とは?
最強のDB設計とは?どのようなものか、例を以下にご説明します。
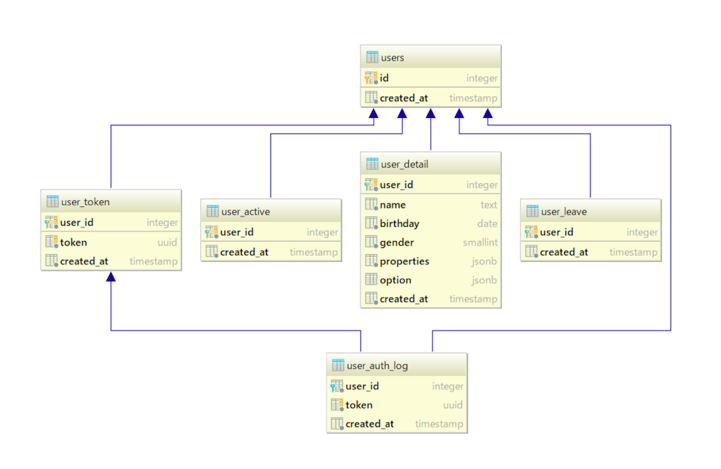
要件としては、User情報を保存するときにどのようなテーブル設計を行うかを想定しています。
users
親tableであり、すべてのユーザはここに属します。基本はINSERTのみでUPDATE、DELETEを考慮しません。
user_detail
userに付随する詳細の情報がここに登録されます。一般的にusersにカラムを増やしたいような内容はここに登録します。なぜusersにカラムを増やさないのか?ですが、それはusersは親tableであり、親tableの更新は常にデッドロックのリスクがあるからです。
properties
propertiesは主に住所や電話番号、必ず登録するユーザの情報を想定しています。JSONB型を採用しています。PostgreSQLの性質として式INDEXの機能があるため参照の速度はJSONB型を利用しても問題ないです。これにより簡単にスキーマレスの設計を実現することができます。ただし大きな問題点としては、部分更新に弱いこと、値に対する制約が弱いということです。
option
optionは、オプションの言葉の通り必須ではない項目を想定しています。JSONB型を採用しています。
user_token&user_auth_log
user_active&user_leave
user_token&user_auth_logとuser_active&user_leave user_token&user_auth_logはよくあるtableです。
このようなtableの際に問題になるのはusersのレコードを削除すると外部キー制約としてこれらのtableが紐付いているため、usersのレコードを削除出来ないことです。残念ながら、外部キー制約を外したり、usersに delete_flag というカラムを追加したことがある方も多いかもしれないですが、それを防ぐための仕組みがuser_active&user_leaveです。ユーザの状態に合わせてtableを作り、状態が変わればtableを移行させてやることで対応することができるのです。
SQLやシステム的にも有効なアカウントを見るときはuser_activeだけを見れば良いです。必要な情報は多くはuser_activeとuser_detailをJOINすることで可能になります。JOINのコストはお互いに主キーなので多くのケースは1対1です。ここが今回の本質です。
この設計は状態毎にtableができますが、親tableのusersは基本的に減ることが無いです。そのためusersはどんどん肥大化していきます。そしてusersをいざ消したいというときに関連する子tableが多いので削除の手順が煩雑になりがちでusersにdelete_flagカラムを作るという本末転倒な状況が稀によくあります。
これの対策としては外部キー制約のCASCADEを利用することですが、多くの場合はlog系のtableを削除する時に処理時間がかかりシステムを圧迫します。1段階踏み込んだ対策は1対1のtableのみCASCADEし、log系のtableはRESTRICTにしておき、先に消すか SET NULL を設定する方法です。
しかし、logは別途残したい場合は同じテーブル構成のoldスキーマ*などを作ってそちらに移すなど運用になってしまいます。usersを消したいという要望は多くはサービスが大きくなっており、シャーディングを検討するフェーズだったりするので更に問題が大きくなります。
この場合の答えはケースバイケースとしか言いようがないので、類似のケースで例えばissueやBlogのような場合で親tablegが肥大化する場合は最初に検討したほうがいいと考えています。
スキーマとは?
コンピュータ・プログラミング手法における論理構造や物理構造を定めた仕様。データベースにおけるデータベース・オブジェクト(テーブル・クラス・ビュー・シノニム・ユーザー権限)などの集合体。スキーマの集合体がインスタンスになる。データベース用語としては、データベースの仕様を記述、定義したものという意味。COBOLでいうと、データディビジョンの部分。
「僕の考えた最強のDB設計」の記事で、より詳しく説明しています。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込むデータベースを学ぶには?「アウトプット駆動」の重要性
成長の壁を乗り越えるための「アウトプット駆動」
データベースをどう学ぶべきかについては、成長戦略の考え方をお話したいと思います。
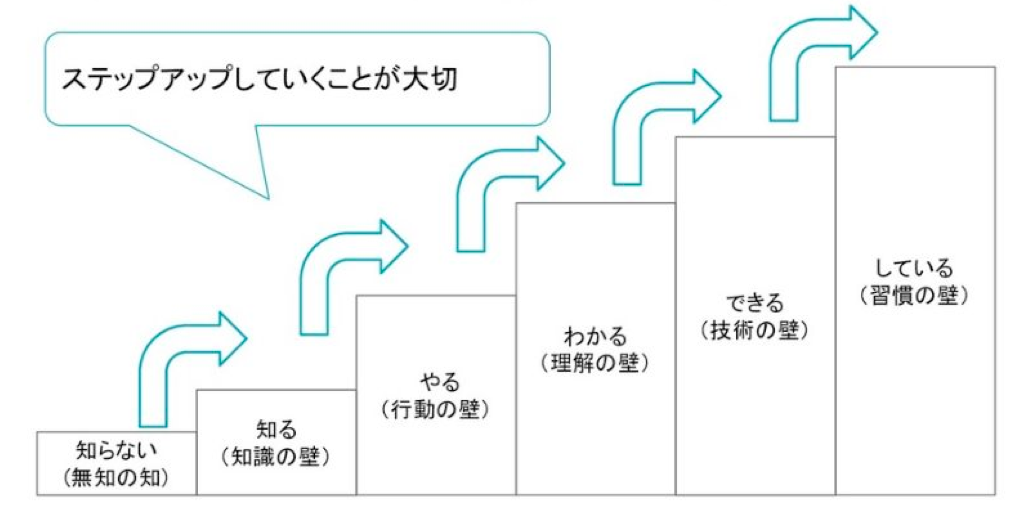
上記のように学習にはいくつかの壁が存在しているので、それらを段階的に乗り越えなければなりません。重要なのがステップアップの方法なのですが、ここではラーニング・パターンの考え方にある「アウトプット駆動」を推奨したいと思います。自分の知識や経験をアウトプットすることで成長していくということで、非常に効率的な手法です。
例えばアウトプット駆動をするために勉強会を利用するとしたら、以下のようになります。
<知る(知識の壁)>
知らないことを知るために勉強会へ行く、知らないことを知っている人を勉強会に呼ぶ
↓
<やる(行動の壁)>
勉強会で学んだことをやってみる
↓
<わかる(理解の壁)>
勉強会で発表するために学ぶ
↓
<できる(技術の壁)>
カンファレンスに登壇者として応募する
↓
<している(習慣の壁)>
繰り返した先に成長がある
これは実際に私が技術を本格的に学ぼうと決意した25歳のときに実践した方法です。業務に紐付かない知識を専門的に学びたいが、時間にもお金にも余裕がない。そんなときに「勉強会で登壇すること」を納期として決め、そこに向けて勉強せざるを得ない状況を作りました。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込む最後に
都市部や地方のコミュニティへの参加について
 曽根壮大さん 日本PostgreSQLユーザ会の理事 合同会社Have Fun Tech 代表
曽根壮大さん 日本PostgreSQLユーザ会の理事 合同会社Have Fun Tech 代表東京の勉強会やコミュニティは著名なエンジニアと出会える機会が多い点がメリットなのですが、地方であってもこういったものはどんどん利用しましょう。地方だからこそ参加者と濃密なコミュニケーションが取れたり、コミュニティ自体が多様であったり、コミュニティ同士の繋がりが強かったりと、都市部には無いメリットがあるからです。
私は現在、日本PostgreSQLユーザ会の理事を務めており、各地で勉強会の開催を担当しています。(イベント一覧はこちら)初心者から上級者までさまざまな層に対してコミュニティを提供していますし、全国に支部があるので地方での勉強会も支援しています。講師として登壇することもあります。機会があればぜひ参加してください。
案件探しの悩み交渉の不安、専任エージェントが全てサポート
今すぐ無料キャリア相談を申し込む



